How I Git It - Syncing
This is part 4 of my serie on How I Git it. You can read Part 3 here.
Pull in new commits from another branch⌗
When working in a team, I will usually be working on my own private branch. Naturally, other team members will be making contributions to the public develop/master branch leaving me behind “in the past”. Some times that’s alright because I’m working on something completely separate, but often I want to get up to date for various reasons:
- Changes have been made that are in conflict with my changes, and I want to resolve those conflicts now rather than later.
- Changes have been made that will benefit me. E.g. an annoying bug has been fixed or maybe a new utility class that I now want to use.
- Changes have been made to an area of the code I am about to enter. Updating now will avoid possible merge conflicts later.
- I am working on some feature and have been stubbing an API that until now, didn’t exist.
- I am code reviewing a team member’s pull request but for some reason, switching to that branch is a lot of hassle (maybe my own branch uses another version of the database schema and migrating down would delete all my meticulously input test data). So instead I’ll pull that branch into mine for the time being.
- I’ve seen many people use git merge as the tool for this. It will create a merge commit every time I pull in something new, and I will get a git history looking like this:
This might quickly evolve into Guitar Hero
Maybe someone who uses this approach a lot doesn’t get confused (?), but I sure do. And again, I prefer rebase, to avoid the merge commits and to get a linear history:
My branch and master have diverged. Rebase to the rescue!

My branch is now up to date with master
This works just as well with other team member’s branches that have been pushed remotely (e.g. GitHub) but haven’t been merged to master yet.
A word of caution when rebasing on other team member’s branches: I treat those branches as “hands off, read only” and purely for testing or previewing changes. When done, it is a good idea to rebase on develop again and drop the commits from that other private branch. Otherwise, those commits will often cause my copy of them to get outdated. That’s because my team member also “Git it like me”, using rebase to edit commits and mess with the history.
Solve merge conflicts like they never happened⌗
Solving merge conflicts correctly can be tricky if not aware of why they happened and what’s going on. I think that’s one of the main difficulties and the cause of a lot of frustration when people are starting out learning Git. I’d like to point out that merge conflicts are just a fact of life when multiple people are working in the same file. It has nothing to do with Git itself. Git is just a tool that I have to manage that fact.
Of course, when I was new to git I got myself into merge trouble a whole lot more than I do these days. I think mainly because I now pay more attention to what others in my team are working on, and rebasing on develop whenever they merge their work. This lets me tackle merge conflicts incrementally instead of dealing with them all at once at my own merge attempt into develop.
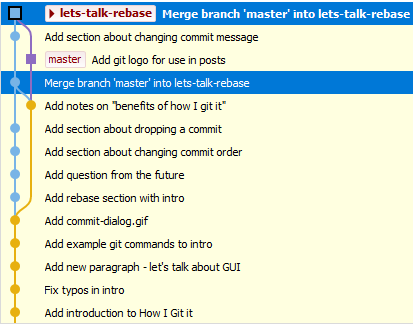
So let’s say there’s been some updates to master, leaving me and my branch behind:
Someone added a footer for use on my blog. Sweet, let’s check it out.
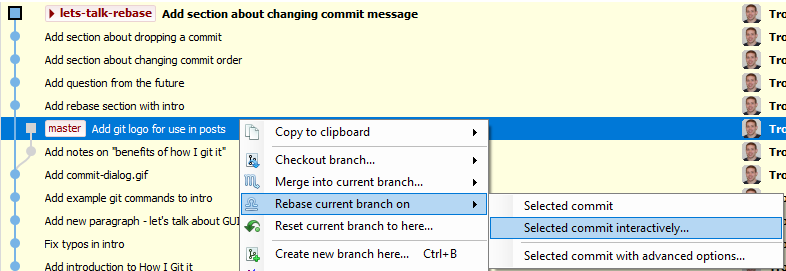
I rebase on the master branch, like I showed in the previous section about pulling commits in from other branches. But this time, it doesn’t go as smoothly:
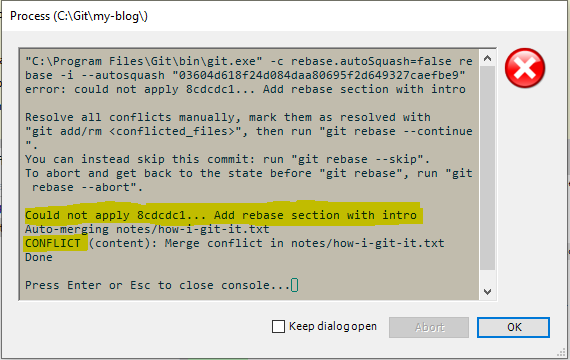
Oh noes, a wild merge conflict appeared!
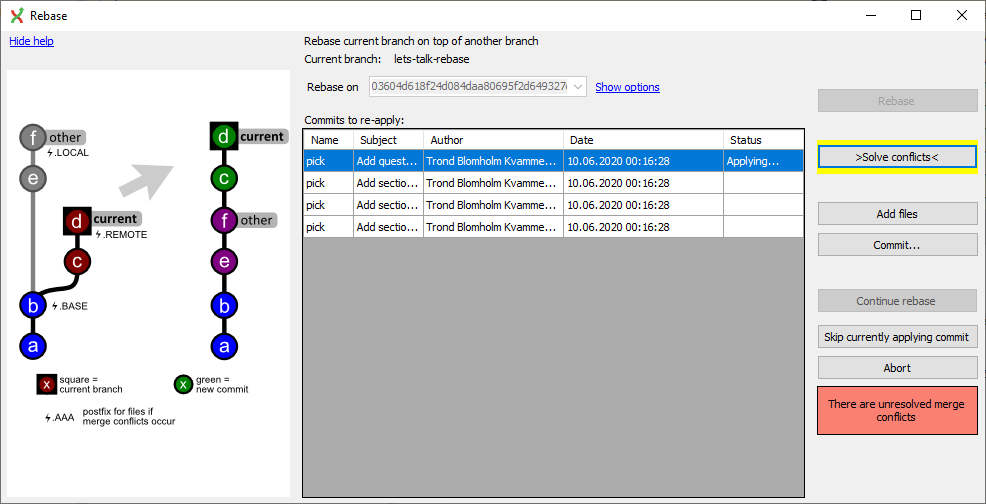
Git Extensions suggests I solve the conflicts. Not a bad idea at all.
At this point, I usually open up the commit dialog again, where I can easily see which files had conflicts:
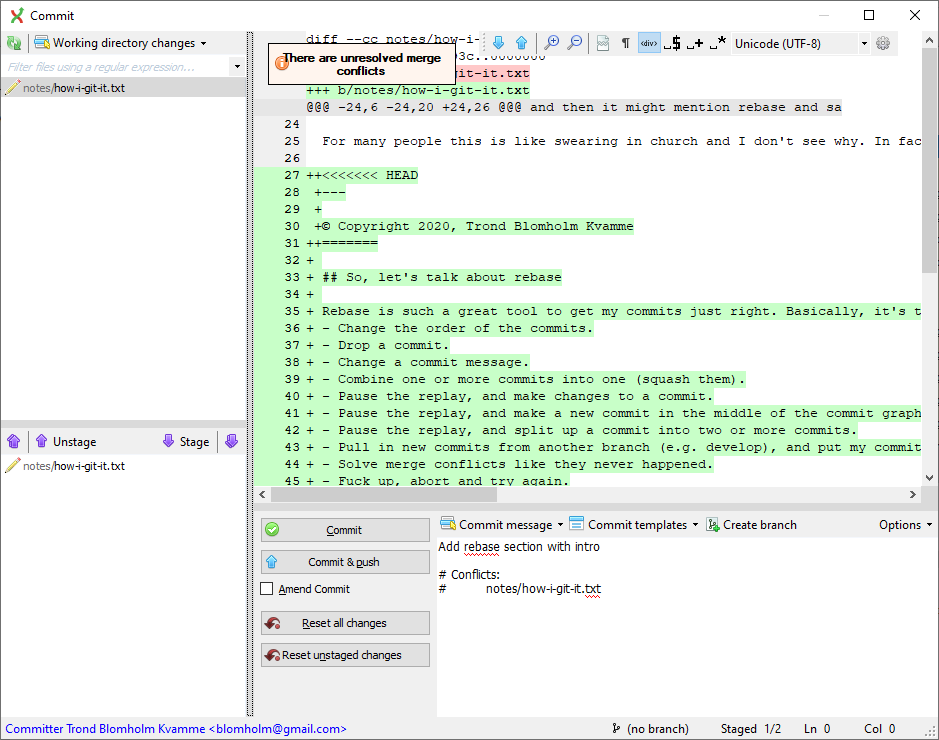
Git Extensions really doesn’t like unresolved merge conflicts. Neither do I.
I like to use Visual Studio Code for resolving merge conflicts.
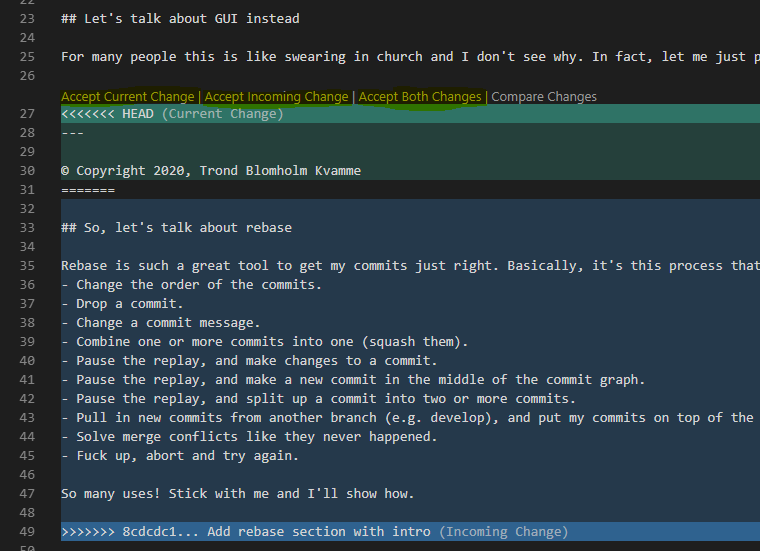
Visual Studio Code finds and highlights the conflicting sections of the file.
I already mentioned that solving merge conflicts isn’t really the topic of this post, but I’d like to add a bit about my thought process on this and how it relates to rebase.
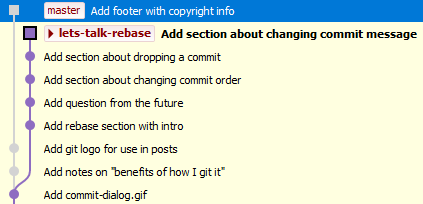
When I started my branch off of master, all was good and my work was just an extension of the master branch really. But then someone came and added this footer to the file where I had been writing stuff.
So now I’m in a branch where that footer doesn’t exist, that is, until I started the rebase process. I basically told git that I want to put all of my work on top of the latest version of the master branch. Git will go ahead and do just that, commit by commit until possibly a merge conflict happens.
I had been adding section upon section to the end of the file and naturally my sections will crash with the footer that was also added to the end of the file. Git can’t possibly know what is correct here, so that’s why git is asking for my help. I have to solve that conflict.
Mentally I try to think of it like: “Ok, what would my text (code) look like had I known about this footer beforehand?”. And the answer is that I would have added the section above the footer. Not at the end of the file.
Then I’ll do exactly that:
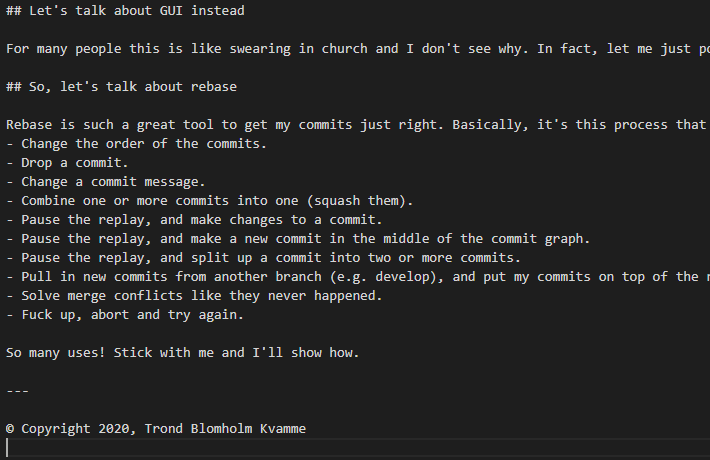
Footer at the end. Makes sense.
After that it’s only a matter of saving and staging the file(s):
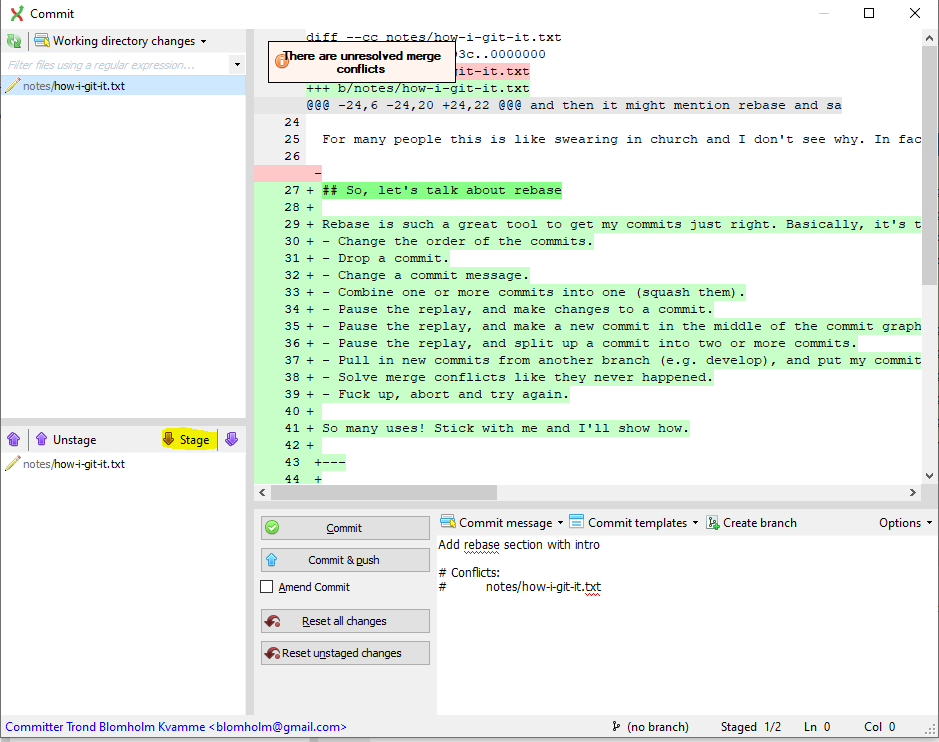
Stage file and close the dialog. I’m going to continue the rebase.
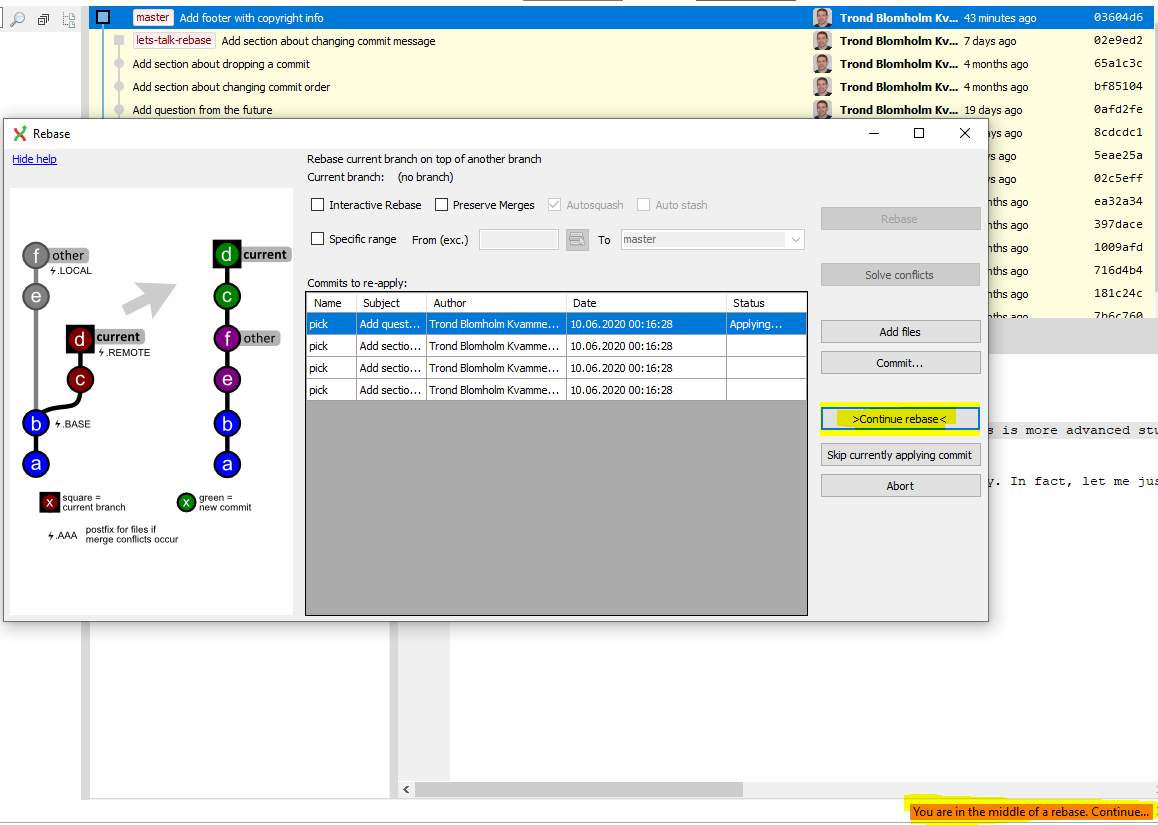
With the merge conflicts solved and staged, I can continue the rebase process, tackling any merge conflicts likewise until done.
Finally I end up with a linear history where my work is just an extension of the master branch again. Life is good.
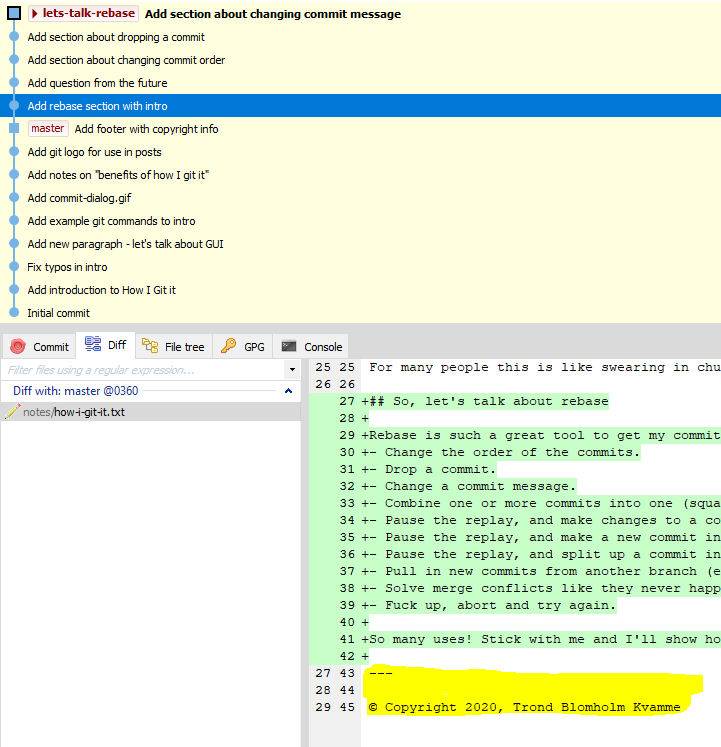
Merge conflict…what merge conflict? Always been like this for sure!
Viewing the history now it appears as if the footer had always been there, and that my sections were added above it.
I think doing it incrementally like this is much easier to handle, and it makes the history easier to understand later because it makes it all happen chronologically.
The alternative would be to merge my branch into master and solve all conflicts as part of the merge commit. Here’s how that would look:
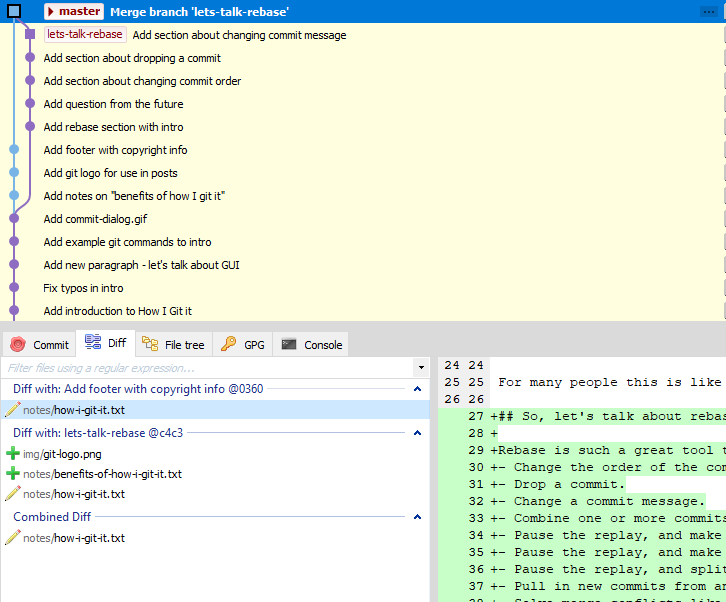
I don’t really get the benefit of this approach, but I think some people like to be able to view the branch and the code within it as it was when it was being developed from the starting point. And with the merge commit they can diff the merge changes with both the master branch and the feature branch to see how code, kind of arrived and merged from two separate branches to one common branch.
But to me it’s just a bit confusing, especially when there are many and larger merge conflicts. To save the conflict resolving for the very end seems like a big risk to get stuff wrong. What if some rather major changes happens and I have to redo my entire approach in the merge commit? Basically making my commit history useless since the playing field changed. Fixing it all in one last big merge commit goes against my desire to make logically atomic commits. And what’s worse, it’s a waste of time for my code reviewer, who would go through my earlier commits only to find out in the end that it all changed. Very annoying.
Merging master into the feature branch more often might be better in that case, but I would end up with the guitar hero history as I showed earlier. No, I’ll stick with rebase, and I’ll adjust my code according to whatever happens on the master branch as I go along.
Finally, my work is complete! At least, until it’s torn to pieces in code review… but for now, it’s complete. That feels good. The next part is about pushing my work and wrapping it up.